论文:SEQ2SEQ-VIS: A Visual Debugging Tool forSequence-to-Sequence Models
作者:Hendrik Strobelt; Sebastian Gehrmann; Michael Bhrisch; Adam Perer; Hanspeter Pfister; Alexander M. Rush
发表:IEEE VAST 2018
1. 简介
本文介绍了一种针对 seq2seq 模型的可视化调试工具 Seq2Seq-Vis,从而更高效地进行分析和调试模型。
2. 背景
Sequence to Sequence
RNN最重要的一个变种,也叫Encoder-Decoder模型
基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder,encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义。decoder则负责根据语义向量生成指定的序列。
这个模型不限制输入和输出的序列长度,应用非常广泛。主要包括:机器翻译,自然语言生成、图像描述以及文本摘要等。
Attention-based Model
指的是神经网络模型增加Attention机制
具体来说,当人们注意到某个目标或某个场景时,该目标内部以及该场景内每一处空间位置上的注意力分布是不一样的。举例:翻译“Tom chase Jerry”中的Jerry时,“Tom”,“chase”和“Jerry”分别拥有不同的attention权重,即这三个词对翻译后的“杰瑞”有不同的影响力。
本文模型
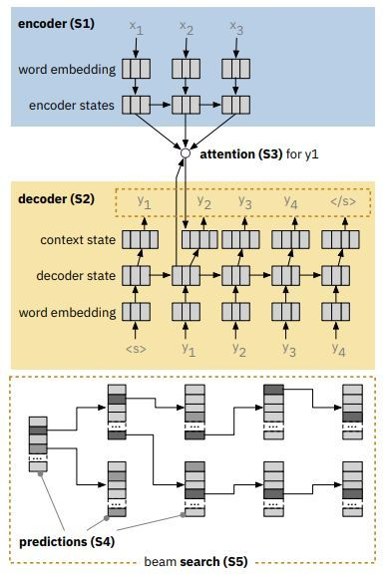
seq2seq 模型通过五个阶段,将源序列翻译为目标序列:(S1)Encoder:将源序列编码为潜在向量(S2)Decoder:将其解码为目标序列(S3)Attention:编码器和解码器之间注意力联系(S4)Prediction:在每个时间步骤中,预测单词概率(S5)beam Search:集束搜索。
重点讲一下beam Search:
Seq2seq模型在给定前缀的情况下预测所有下一个单词的概率。虽然人们可以在每个时间步骤中简单地采用最高概率词,但是这种选择可能导致错误的路径。设置Beam Size为k,永远选择所有序列中概率最大的k个。一旦所有K个光束通过生成停止标记而终止,则最终预测是具有最高分数的翻译。
3. 动机
![]()
黑箱问题
- 神经网络模型的复杂结构导致不可解释性和不确定性。
- 决策过程的不透明导致无法追踪错误源头。
4. 本文工作
Seq2Seq-Vis——针对 seq2seq 模型的可视化调试工具,使用户可以可视化模型执行过程中的注意力、单词预测、搜索树、状态轨迹和近邻词列表等,从而更高效地进行分析和调试。
目标
检查模型决策:允许用户理解、描述并具体化模型的错误。
连接样本和决策:通过关联内部状态与相关的训练样本来描述模型决策。
测试可选决策:可以对模型内部进行操作。
任务
创建模型所有五个阶段的常见可视编码。
通过查询大型训练样例数据库,实现最近邻搜索。
为模型的不同阶段生成合理的替代决策。
5.可视化设计
界面概览
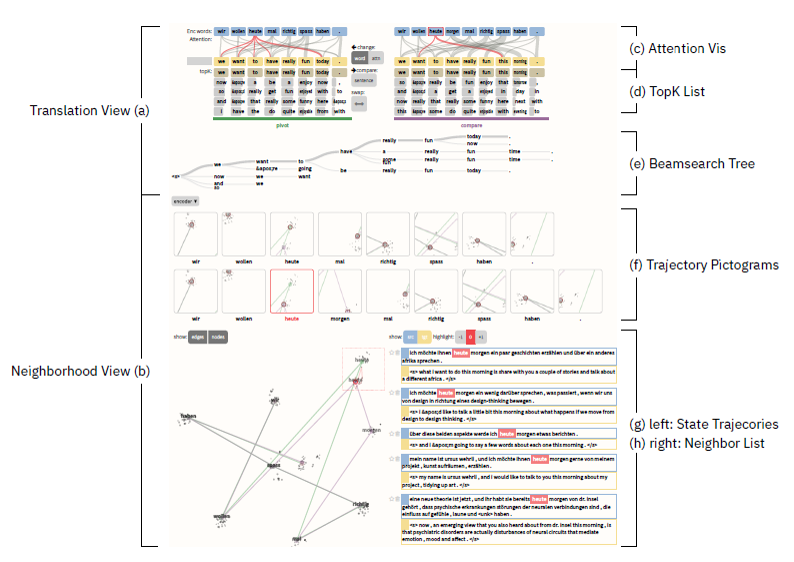
翻译视图(Translation View)
E:编码器以蓝色显示。
D:解码器以黄色显示。
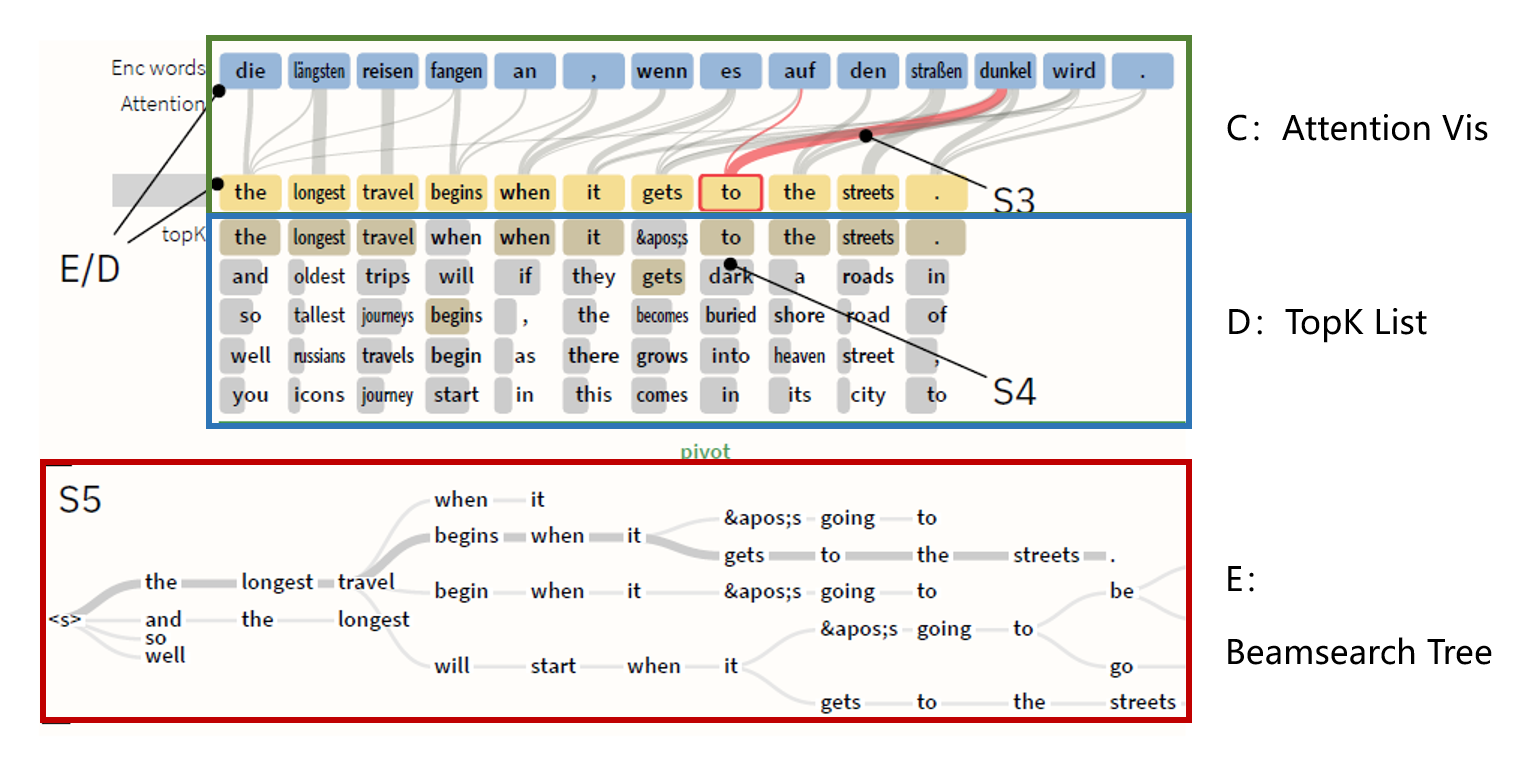
Attention Vis:注意力通过加权的二分连接显示。为了减少视觉混乱,对注意力图进行了修剪。
TopK List:每个时间步的前K个预测。每个词的概率采用条形图编码,黄色高亮显示它最终选择结果。
邻域视图(Neighborhood View)
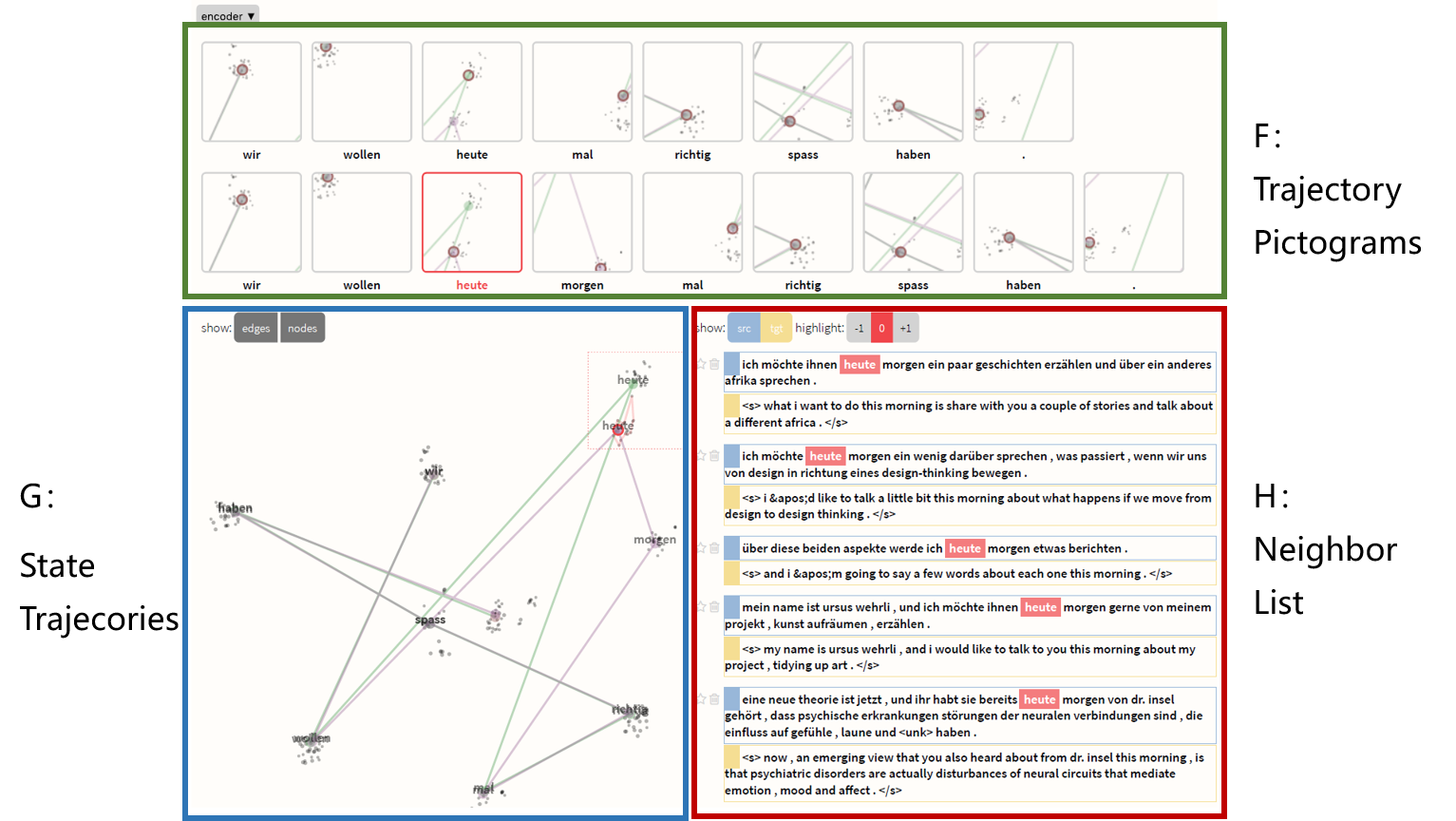
Seq2seq模型在每个阶段产生高维向量,例如编码器状态,解码器状态或上下文状态, 很难直接解释,但我们可以通过查看产生类似向量的样例来估计它们的含义。
G反映的是预先计算好状态的数据集的最近邻域的状态轨迹(采用t-SNE或MDS投影)。为了便于理解较长轨迹,F视图中每一个小窗口都是G视图中的切分,重点关注每一个词。H反映的是最近邻域列表。
交互
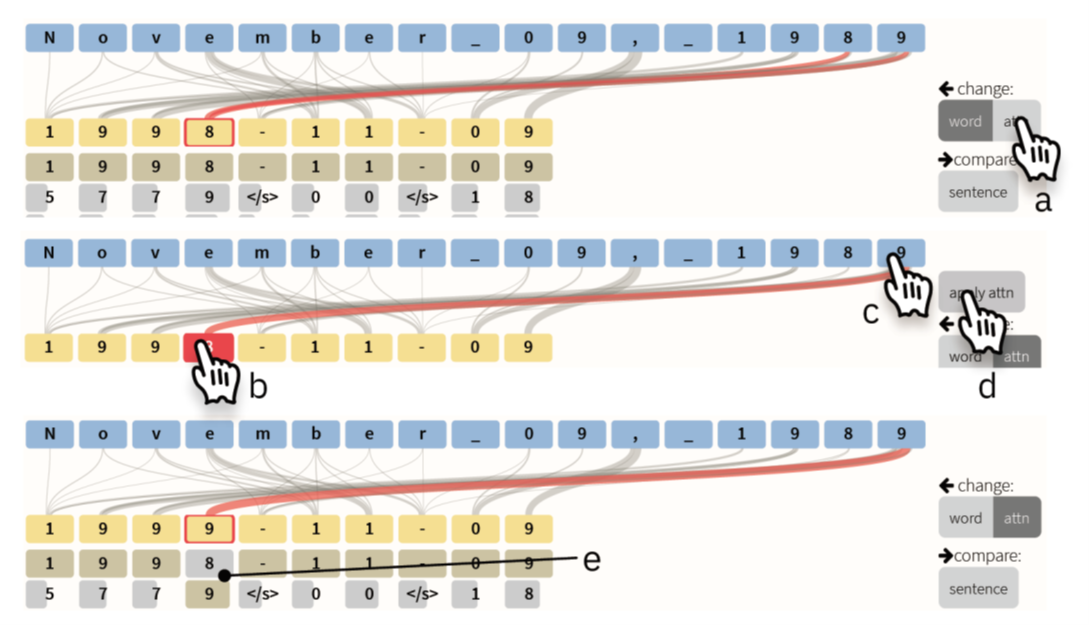
model-focused模式:直接修改模型。
切换成更改attention权重模式。b.选择target中待修改权重的词。c.重复点击encoder中的词,为其赋予更大的权重。d.最后确认修改。e.模型被更改,会按照新给定的权重重新计算。
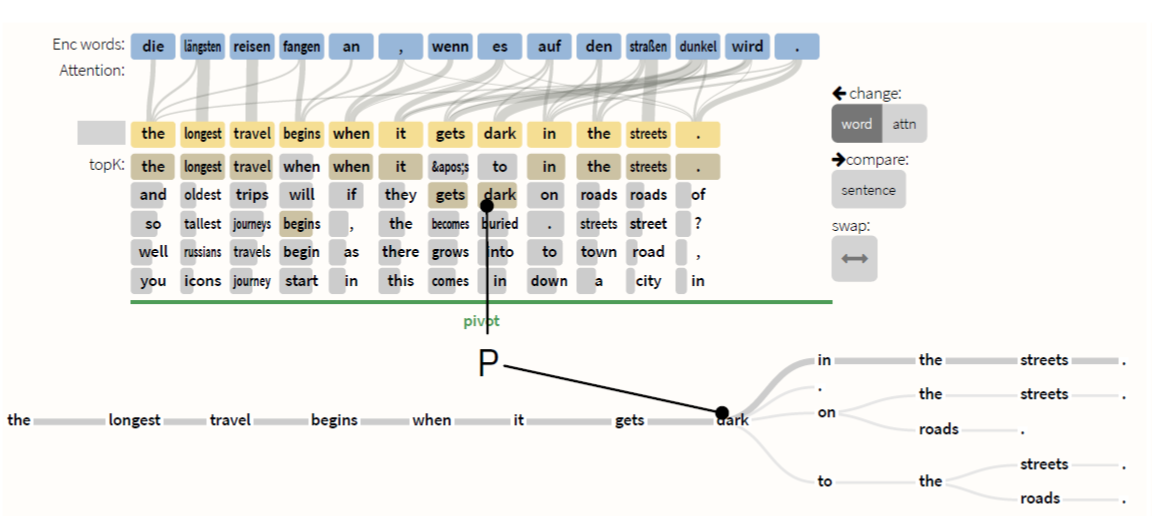
language-focused模式:1.更改source和target,触发比较模式。2.从TopK List中手动选择最佳单词。触发前缀解码,在特定路径P上强制进行集束搜索。
6. 总结与未来工作
总结:
针对机器翻译中最常用的 Seq2Seq 模型,提出Seq2Seq-Vis可视化调试工具,能够深入探索模型的所有阶段。
既能可视化模型的决策过程,又允许开发人员直接修改模型。
未来工作:
改进投影算法。
扩展支持的序列类型,包括音频,图像和视频等。
✉️ zjuvis@cad.zju.edu.cn